This site archives newsletters dedicated to my open biology courses taught from Georgia State University in Atlanta, GA. The course focuses on the principles of cell and molecular biology. You are welcome to use the material, but please provide a link back to this blog.
The Lac operon, a classic example of bacterial gene regulation, and set the stage for understanding Eukaryotic gene regulation. While Eukaryotes can possess the equivalent of operators, there are more complex levels of regulation to help determine the differentiation and physiology of cells. As we move to eukaryotic cells, we find that there are other ways that gene expression can be regulated. Below are a few examples. If you want to learn more about Eukaryotic Gene regulation, this page from the NCBI Bookshelf gives a good overview: Regulation of Transcription in Eukaryotes.
Transcriptional control: This is control of the promoter and operator, and is very similar to what was seen with the Lac operon.
Enhancers and Activators: Enhancers are sequences on the DNA that are found away from the initiation site (promoter). Activators are proteins that bind to enhancer sequences and help regulate the RNA Polymerase complex. This allows for variable expression of the gene. Eliminating one enhancer does not abolish transcription, but can reduce the efficiency of transcirption.
Epigenome: This occurs in both prokaryotes and eukaryotes. In eukaryotes, the epigenome is noted by chemical changes to DNA and histone molecules that result in changes to the chromatin strand. These changes can "lock down" genes, preventing even the recognition of the promoter.
IMPORTANT: the epigenome does not represent mutations. Instead, it is a reversible chemical alteration to chromatin structure.
This chromatin alteration can be passed vertically to offspring.
Changes to the epigenome occur due to chemical signals and environmental changes (they change the organisms adaptation range).
DNA Methylation (Epigenetic): Methylation of cytosine (the nitrogenous base of the nucleotide) prior to a promoter reduces transcription rates of the gene, or can inactivate the gene.
Post-Transcription regulation: If you don't add the 5' cap, then RNA can't leave the nucleus. If you don't add the 3' poly-A tail, RNA is digested. If you don't splice out the introns, you don't have a code. Prevention of post-transcriptional modification can play a role in gene expression.
Epigenome Videos
GOAL
At present, I want you to concentrate on gene regulation at the promoter. This includes the concepts discussed in regards to the Lac and Trp operons, as well as enhancers and activators. Having an idea of how chromatin remodeling works will also help in regards to eukaryotic gene regulation. In subsequent semesters, these concepts will be the foundation for further exploration of gene expression.
One of the most well-studied gene regulation systems is the Lac Operon found in Escherichia coli. To understand this system, it is important to first understand that bacteria do not experience Transcription and Translation in exactly the same way as eukaryotes (the mechanics are very similar, but there are some distinct differences).
The core difference between prokaryotes and eukaryotes is the nucleus. Since bacteria lack a nucleus, transcription takes place in the cytosol. There is no need for a tag to get out of the nucleus, so there is no need for capping. Also, there are no introns, so no need for splicing. Basically, there is no processing of RNA to make mRNA. There is no pre-mRNA. When a gene is transcribed, the transcript is mRNA.
Since there is no membrane separating transcription from translation, you can couple these to processes. As mRNA is made, it can be translated (polyribosome).
Bacteria have a single circular molecule of DNA (a genophore, not a true chromosome). They have to conserve their genetic space, so bacteria combine genes for a metabolic process in a single mRNA. IMPORTANT: bacteria can combine genes for a metabolic pathway into a sequential sequence with a single promoter. Thus, when you transcribe, you get all the genes for a given metabolic pathway.
The word OPERON describes this unique arrangement of prokaryotic genes: One promoter and one operator for a given series of metabolically linked genes.
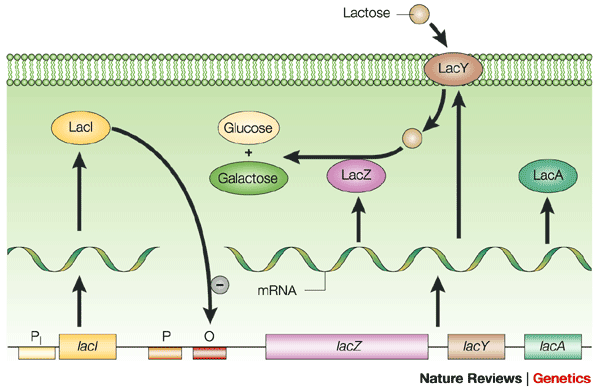
The lac Operon holds three genes that give the cell the ability to take in and use the sugar LACTOSE. [Image Note: Bacteria have two promoter regions, -10 & -35, for a given gene or operon]
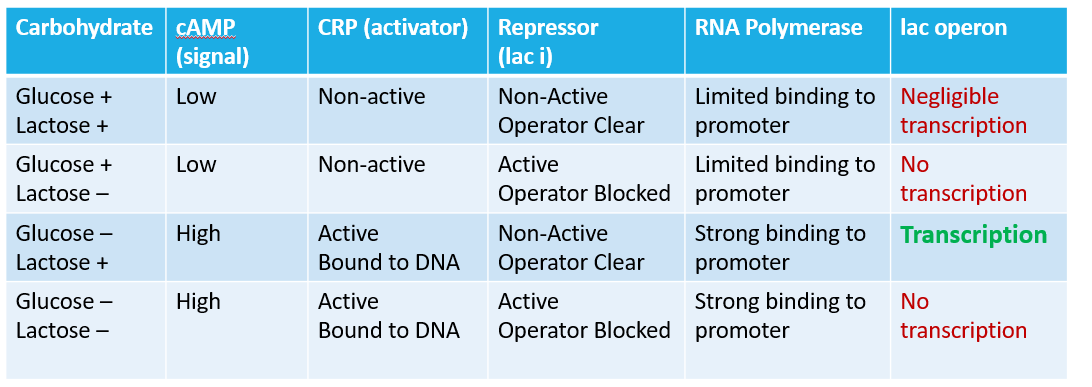
For E. coli, glucose is the preferred sugar. When glucose is present, there is no need to use lactose: these genes are not transcribed. When there is no glucose, E. coli has to use other sugars. IF lactose is present, the genes for lactose utilization will be made. Conversely, if there is no lactose, they genes remain locked down.
Glucose Present: No transcription
Glucose Absent: Minimal transcription
Glucose Absent, Lactose Present: Transcription of the lac operon.
NOTE: In this example, there are two ways to control the expression of a gene or operon:
You can block the operator of the gene. This prevents RNA polymerase from making RNA.
You can alter the promoter (or the interaction between transcription factors and DNA) to prevent binding of the Transcription Complex (RNA polymerase).
Negative Transcription Regulation (Repression) in the lac operon: There is a repressor for the lac operon. This is a protein that can bind to the operator of the lac operon (that region immediately downstream from the promoter). This creates a physical block that prevents RNA polymerase from transcribing.
The lac operon repressor (LACI) is a protein that is constitutively (always) expressed. This indicates that the lac operon is normally turned OFF. Notice that the gene for the regulatory protein is upstream from the lac operon. The lac repressor (LacI) binds to the major groove of the DNA at the operator. As you can see in the annotated image of the repressor, you have a DNA-binding region (active site), and a regulatory domain. The regulatory domain has the ability to bind to Lactose (the inducer).
You must have a way to unlock the operon, or to put it another way, to inactivate the repressor. An inducer is a ligand that can bind to a regulatory domain, changing the shape of the regulatory domain, and thus inactivating the DNA-binding domain. In the case of the the lac repressor, the ligand is allolactose (a derivative of lactose). When allolactose binds to the lac repressor, the repressor is inactivated, and the operon cleared. This is seen in the image below.
Therefore, the lac operon is partially regulated by the presence of lactose in the environment. If there is no lactose in the environment, then there is no need to transcribe the three genes needed to use lactose.
Remember, we don't want to expend energy for things we don't need. Below is the size of the three gene products:
β-Galactosidase 1,024 Amino Acids
β-Galactoside Permease 418 Amino Acids
β-galactoside transacetylase 203 Amino Acids
Total Amino Acids, 1645. Using the assumption of 4 ATP per amino acid added to a protein, that makes 6580 ATPs needed just for protein synthesis. With this many amino acids, you are also looking at 4935 nucleotides (remember 3 nucleotides = codon = 1 amino acid), plus at least 3 stop codons. Each nucleotide added to a transcript takes the equivalent of 1 ATP, so you are looking at 4944 ATP minimum to make the transcript. Just to make one example of each protein (gene product), you are looking at 11,524 ATP. Do you just make one example of each protein? NO! Do you have the idea that this is energy consumptive? Would you make it if there was no lactose around?
Tomorrow we will look at the positive regulation of the lac operon. Remember, you still will not transcribe this operon if glucose is present. You only transcribe when glucose is absent. So how does the operon know when glucose is absent? That will be our discussion tomorrow.
Challenge
In your own words, describe how lactose (allolactose) is used to regulate the transcription of the lac operon. In your discussion, make sure that you explain the concept of an operon, and discuss the differences between eukaryote and prokaryote gene transcription.
The Lac operon has two levels of regulation. The first is through a repressor protein that binds to the operator of the operon. The repressor is constitutively expressed and binds to the Lac Operon operator. When lactose is present, it binds to the repressor, thus changing the shape of the repressor protein; the repressor detaches from the operator, and transcription can occur.
There is a second regulation system for the Lac Operon, and it has to deal with the promoter and the CRP binding site. In the case of the Lac operon, the promoter is "weak". RNA polymerase does not readily bind to the promoter. To assist in binding RNA polymerase, there is an activator site (CRP binding site) that can be used to "enhance" the promoter (enhance the binding of RNA polymerase to the promoter).
CRP stands for cAMP Regulator Protein (it is also known as the Catabolite Activator Protein). CRP has a binding site for cAMP, and the protein is activated (turned on) when cAMP binds. The CRP-cAMP complex can bind to the CRP binding site, and alter the Lac Operon promoter, enhancing the binding of RNA Polymerase to the promoter. But why this second regulatory system?
Remember that for this cell, glucose is the preferred carbohydrate and energy source (Escherichia coli is a chemoheterotrophic organism). The first regulatory system for the operon dealt with the presence/absence of Lactose (you only transcribe the operon when lactose is present). This second deals with the presence/absence of glucose. Glucose is the primary carbohydrate source, so as long as glucose is present, there is no need to transcribe pathways for secondary sugars.
In bacteria, the movement of glucose across the membrane (remember hexokinase?) inhibits the production of cAMP. If glucose transport slows dramatically or stops, Adenylate Cyclase begins making cAMP. So, while glucose available, there is little to no cAMP in the cell. When glucose is scarce, we see an increase in cellular levels of cAMP. For bacteria like E. coli, we can see cAMP as a starvation signal. The CRP-cAMP complex will bind to the bacterial DNA molecule and activate numerous pathways for alternative carbohydrate utilization. As with the Lac Operon, these other pathways will only transcribe when the correct sugar is in the environment.
Below is an image that demonstrates the two components of regulation.
Explain in your own words the evolutionary advantage of having a two-stage regulatory system, as seen in the Lac Operon. In your discussion, explain why it is important to have secondary messages like cAMP act as signals for large environmental changes, such as starvation states.
Reading textbooks and supplemental material is critical to becoming a successful student, as reading is an extremely effective way of learning if done actively. Active reading means you are critically engaged with the material covered in the textbook. You are forming questions, building summaries, and thinking about the topic. There are a number of active reading techniques out there, but they are not "one-size fits all". You need to experiment to see which technique works for you. As a note, give each of them a try; you won't know what works until you try it. Here is a video to help you consider different ways of reading the textbook.
Suggested Reading
These brief articles are a supplement to the readings from your textbook on Gene Regulation. You do not have to finish these articles today, but they will help you understand gene regulation at a deeper level. They also make great references for your next milestone paper.
Do we express all of our genes at the same time? Why?
Do we need all of our genes expressed all the time? Why?
Why do we have so many genes?
These are just a few of the questions you need to start asking yourself. Humans have hundreds of thousands of genes. Many are needed all the time (constitutive), but others are only needed when the cell get's certain signals. So how do we control the expression of all this genetic knowledge?
Think about the human body and homeostasis. Think about hormones. Are you always producing everything, or do you need to trigger some events? Remember that you need at minimum the equivalent of 4ATP per amino acid incorporated into a protein. Add to this 1 ATP equivalent for each nucleotide during transcription. You should quickly realize that gene expression is energy expensive.
The regulation of genes is a very active field of research. Biologists are looking at gene regulation dealing with the initial development of complex organisms, e.g. embryology, and the interaction between you and your microbiome (microbial community associated with an organism). In order to understand this current research, you need to first understand the basic regulation systems. To give you a hint at the importance of gene regulation, look at the following video.
Daily Challenge
Why do we need gene regulation? Today, reflect on the need and use of gene regulation. Why would an organism need to have some genes that it could turn on or off? Why would you need to control gene expression? Can the environment affect gene regulation? Can gene regulation affect evolution?
Thursday, February 1, 2018
Study Skills
It is always helpful to reflect on your study skills and see if there are ways you can improve your learning. Today, consider whether you maintain focus when you sit down to study.
Figure 1: chemical structure of an amino acid
Amino Acids and Polymerization
Amino Acids and ProteinsProteins will be a reoccurring topic throughout the semester, so for today let's first review amino acids and the basics of biochemical polymerization. They are one of the informational biopolymers. This means that they are composed of monomers (amino acids) that are linked together in specific sequencesthat are critical to their overall structure and function. [NOTE: It is important to understand the terms monomer and polymer, so make sure you have a good definition of these terms in your notebooks.] To understand proteins, we must first understand their monomeric unit, the Amino Acid. Remember that all monomers will be chemically similar. In the case of the amino acid, the base molecule of Amino-Chiral Carbon-Carboxyl is the same. The difference in the amino acids comes with the side chain. These functional groups give each amino acid its unique identity and function. The twenty amino acids that are used in natural proteins can be found at the following link: Amino Acid Diagram. Notice that there are four general classes of amino acids with different chemical properties based on the functional group. NOTE: In the diagram to the right, R represents the radical group. This is the functional group or side chain. The distinctive characteristics of an amino acid are determined by the R group.
Figure 2: Polymerization of amino acids by a condensation reaction.
The base molecule is needed to link amino acids together into a polymer. A condensation (dehydration synthesis) reaction is used to form peptide bonds, the specific bond type that links amino acids together. [NOTE: biopolymers (save for lipids which are not polymers) have specific names for the bonds between monomers.] In the formation of a peptide linkage (bond), you will have a carboxyl and amino group linking together, with water being a product.
This linking of amino acids through peptide bonds will create the primary structure of a protein. All of the remaining levels of protein structure will result from interactions between functional groups on the amino acids. Local interactions induce folding into the secondary structures, which will result in other amino acids coming into close contact. This results in a tertiary structure. Finally, you will get a quaternary structure when multiple individuals folded peptide chains come together. Remember that Van der Waals forces (including hydrogen bonds), covalent bonds (disulfide bridges), and hydrophobic interactions will all induce folding. Because of this, environmental factors (such as heat or pH) can influence the folding pattern and shape of a protein.
Protein Self-Assemble (Folding)
Let's now further examine the importance of functional groups by discussing how they help form the working shape of a protein by causing a chain of amino acids to fold.
The primary structure of a protein is a chain of amino acids. Due to how proteins form, one end of the chain will end in an amino group (N-terminus), which the other end will have a carboxyl group (C-terminus). In Between these two terminal points will be a wide variety of amino acids.
The side chains of neighboring amino acids will begin to interact. They could be pulled toward each other, be repelled, or have nothing happen. Remember that the functional groups can twist around the chiral (central) carbon of the amino acid, so repulsion may just force the side chains to opposite sides of the chain (remember, you are dealing with 3-D structures here). The amino groups and carboxyl groups, even though they are part of the backbone, also retain polarity. Thus they can also be involved in the folding.
These interactions start the formation of the secondary level of protein structure. The two most common types of secondary structures are the alpha helix and the beta pleated sheet. These two types of secondary structures will help explain how the amino acid side chains start the folding process.
Figure 4: α-helix
The α-helix relies on neighboring amino acids. Through the polarity of amino and carboxyl groups, the backbone of the molecule begins to twist and hold due to electrostatic interaction (van der Waals forces). The image to the left is an example of an alpha helix. The alpha represents the direction of the twist, and you will learn more about the naming of these in organic chemistry. Notice that in the image there are yellow dashed lines. These represent hydrogen bonds (van der Waals forces) between amino acids. The green ribbon represents the backbone of the amino acid chain (amino-chiral-carboxyl connected to amino-chiral carboxyl and so on). So the interactions (notably from polar partially charged side chains has produced a twist in the primary structure.
Figure 4b: β-pleated sheet
In contrast, β-pleated sheet, shown on the right, has interactions between different regions of the primary structure. While only one amino acid chain is involved, in this case, the chain is not twisting. Instead, neighboring regions become attracted to each other. Also, the electrostatic interaction is between amino and carboxyl groups, not R groups. Multiple regions can be brought together to form these sheets as indicated in the diagram below. In this diagram, the red arrows represent a portion of the primary structure that has begun to form β-pleated sheets. Notice that six red arrows are arranged together. The purpose of this diagram is to show the placement of the β-pleated sheet. Consider a sheet. It is flat with two sides. Why do you think it would be important for a protein to fold in such a way as to create a relatively "flat" surface with two sides?
Figure 4a: β-pleated sheet
Notice that with the α-helix and β-pleated sheet we have altered the structure of the protein. It is no longer a linear chain but has greater dimensionality. We have either turned the protein into a rope/cord (α-helix) or into a "plane" with two faces(β-pleated sheet). Now areas that were once distant have been brought closer together. Now side chains can start interacting with each other.
Figure 5: Tertiary Structure
In the tertiary structure, different regions of the protein are brought into association. Electrostatic and hydrophobic interactions will force more conformational (structural) changes onto the protein. This will lead to a 3-dimensional structure. In the following diagram to the left, you can see an example of
a protein in primary and then tertiary structure.
Notice that the secondary structures are visible, but even these have been folded into each other.
Figure 6: Disulfide bridge
The forces that govern this are found in the R (functional) groups of the amino acids. Hydrophobic areas cluster together. Positive and Negative charges attract, while like charges repel. Polar partially charged side chains further interact, either with each other or with full charged. We also have a new interaction. The amino acid cystine contains a thiol (-SH). The thiols of two cysteines can react to form a disulfide bond. This is a covalent bond. Question: Which is stronger individually, a covalent bond or a hydrogen bond (electrostatic interaction)? The disulfide bond is utilized to stabilize the 3-dimensional structure of the protein.
Figure 7: Quaternary structure (Hemoglobin)
Many proteins are functional in the tertiary structure. Here you will see either globular or linear proteins (like collagen). There is a final level of structure. Some functional proteins are actually made up of multiple individual proteins. A great example of this is hemoglobin. The hemoglobin molecule, seen to the left, is composed of four individual proteins: 2 α-hemoglobin (red) and 2 β-hemoglobin (blue). The green structure is Heme, a prosthetic group that is used to hold oxygen and is attached by electrostatic interactions (van der Waals forces) to the proteins.
NOTE: Some proteins are functional in the tertiary structure, but others are only functional when you have multiple individual proteins forming the quaternary structure.
Denaturation: The protein is held together primarily through electrostatic interactions. What happens when a protein warms up? It starts to unfold. Why? The electrostatic interactions weaken as the kinetic movement of the atoms increases. Acids and bases, with their charged H+ and OH- also disrupt these electrostatic interactions. Secondary and tertiary structures begin to change conformation. Most notably, they unfold. To denature a protein is to unfold it....but....
What if you only apply a mild heat, let's say your muscles warm up due to exercise. What happens to the proteins? What happens to hemoglobin when it passes through a warm temperature? Your muscles are also metabolizing, and as we will see, produce acids. What does this do? So, is denaturation all or nothing?
The tertiary and quaternary structures all have a specific electrochemical profile.
What happens if you add a charged particle/compound to a protein? What happens if I add a new positive charge? Answer: The protein will change shape (conformation).
What will this due to the function of the protein? It could actually activate the protein, but it could also deactivate the protein. This will be a discussion a little later in the semester, but I want you to start thinking about the implications. Example: Hemoglobin
Adult hemoglobin is a quaternary protein, composed of two α-subunits (tertiary proteins) and two β-subunits (tertiary proteins). Each subunit contains a heme group which bears an Fe+2. The heme is a prosthetic group of the individual proteins; without the heme, the subunit is non-functional. We will see further examples of prosthetic groups and other factors as we go through the semester. NOTE: We are looking at adult hemoglobin.
Figure 8: animation of hemoglobin t-r state transformation, made by en:User:BerserkerBen http://en.wikipedia.org/wiki/File:Hemoglobin_t-r_state_ani.gif
To the left is an animated image of hemoglobin. Notice that the configuration (shape) of the protein changes when Oxygen is bound (Oxy) and when no oxygen is bound (deoxy). MEME: When something binds to a protein, it changes shape. In the image, you can also see the various subunits (each a tertiary protein) with their associated Heme groups (heme groups are in red).
The folding of the protein is critical to its function. Even a small error in the primary structure can cause significant changes to the overall structure, and therefore changes to the function.
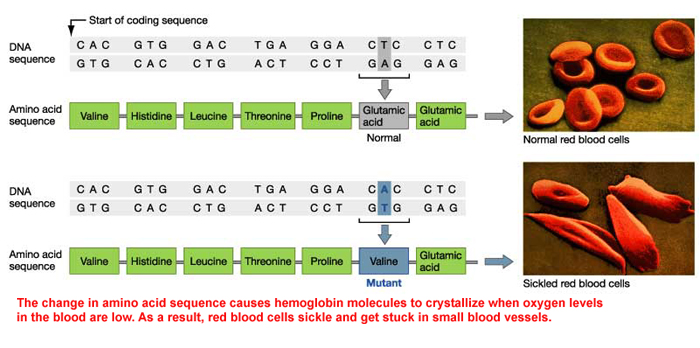
A well-known condition with hemoglobin is Sickle Cell Anemia. The condition is based upon a mutation of the gene that codes for the β-hemoglobin. The switch from an Adenine to Thymine causes a change in the primary sequence of the protein. In wild-type (non-mutant) β-hemoglobin, there is a glutamic acid (charged, negative) at position 6, but in Sickle Cell Anemia, the sixth position holds valine (non-polar). At low oxygen levels (such as in your tissues after exercise), the hemoglobin takes on an abnormal shape (
The quaternary protein has now changed shape by opening up. Sickle hemoglobin has the ability to bond to other sickle hemoglobins. This is due to hydrophobic interactions among valine, and the loss of a salt bridge (ionic interaction). The image below shows the result of this interaction between sickle hemoglobin: clumping.
Figure 10: Interaction between hemoglobin molecules
http://evolution.berkeley.edu/evosite/evo101/images/hemoglobin.gif
The clumping of sickle hemoglobin in low oxygen environments causes the distinctive change in shape seen in sickling red blood cells and is all due to changing one amino acid in the primary structure.
Below is an image comparing the shape of the normal erythrocyte (red blood cells) and the sickle variation.
Figure 11: Normal vs. Sickle Erythrocytes (Red Blood Cells)
Challenge:
Here are two challenges to help you think about protein structure.
Challenge 1
Hemoglobin is a protein that is constantly changing shape due to the presence or absence of oxygen. It also changes shape when in acidic environments or hot environments (think of your muscles after a work out). The effects of temperature and pH are described in the Oxygen Dissociation Curve. Temperature and pH disrupt electrostatic interactions, allowing for proteins to denature. Using the concept of denaturation, explain why more oxygen is released when the pH lowers and temperature increases. How would this be of benefit to the body?
Challenge 2
Antibodies help to defend the body against infections. They work by binding foreign chemical markers called antigens. The diversity of antigens is staggering, and cells that make them (B lymphocytes) have the ability to undergo somatic recombination (programed changes to DNA) to increase the variability of antibodies. Of specific importance is the variable domain:
In the above diagram, look at the Variable Domain of the Light Chain (VL). Notice 3 areas drawn in red, and referred to as the Loops that Bind Antigens. These are the areas where Somatic Recombination can change the nucleotides present in the gene. If I change the nucleotides (as with hemoglobin above), I can change the amino acids in the primary sequence. Explain how changing the primary sequence in these loop regions can change the binding affinity of an antibody to an antigen, and why this is beneficial to the body.
The core concept of translation is the connecting of a codon to an amino acid, which is accomplished with the Transfer RNAs. What that leaves us with then is the actual mechanism of amino acid polymerization.
Initiation of Translation
Protein function is determined by the sequence of amino acids. This sequence allows the protein to fold into the correct configuration to produce activity. Any variation in the sequence can produce alterations to function, or even result in non-functionality. In order to generate the correct sequence, we must first establish the correct reading frame of codons. We must first find the start codon on mRNA.
The small subunit of the Ribosome (40s in eukaryotes) is built to find the Start Codon (AUG) and will align the full ribosome with the correct reading frame. A number of proteins will help the alignment and in the formation of the full (holoenzyme) Ribosome.
The diagram below shows the overall formation of the initiation complex, complete with a tRNA (the yellow structure with a pink circle attached). Again, the function of this replication complex is to find the start codon and set the reading frame for the Ribosome. Notice that the large ribosomal subunit (60s in eukaryotes) only attaches after AUG has been found. As before, it is not necessary at this academic level to memorize all of the factors involved. What is more critical is that it is a multifactor system designed to find the correct start point, and thus the same reading frame.
Key Feature: Notice that the first tRNA is already linked to the small subunit. Why? Its anticodon is complementary to the codon on mRNA. Specifically, it has the anticodon for the start codon (AUG). So we are using base complementarity to find AUG.
Elongation
The polymerization of amino acids occurs during elongation. This is where the P and A sites become important (NOTE: P and A sites are the active sites of the enzyme). P stands for Peptidyl, while A stands for Aminoacyl. These are chemical terms, which shows the orientation of the amino acid. The exit site, represented by E, is not an active site. Consider it a disposal point for spent tRNAs. [NOTE: you may also find references to a fourth site where the tRNA first comes into the complex. Don't worry about this optional site.]
The P and A sites reveal a single codon on mRNA and can hold a single complimentary tRNA. During elongation, when you have a filled P and A site, the amino acid from the P site will be linked to the amino acid in the A site. This is a process that you will have to visualize, so use the diagram below as reference:
The amino end of the amino acid is free. The carboxyl end is attached to the tRNA. Starting at the top of the above diagram, the growing amino acid chain is attached to a tRNA in the P site. A new tRNA with an amino acid (charged tRNA) is brought into the A site. Using GTP, the Ribosome (large subunit) takes the growing peptide chain and links (carboxyl to amino) it to the individual amino acid in the A site. When this is done, the entire ribosome shifts downstream to the next codon (the new codon appears in the A site).
The spent tRNA that started in the P site is now moved to the E site, where it is removed from the ribosome. NOTE: It takes 2 GTP to create the peptide bond, then another GTP to move the ribosome. So a total of 3 GTP are used in one 'round' of Ribosomal action. REMEMBER THIS! In addition, it took a triphosphate to charge tRNA (so a total of 4 for each amino acid added to the polymer).
When both the P and A sites have charged tRNA, the growing chain from the P site is added to the single amino acid in the A site. The ribosome shifts and the process continues. This elongation process of adding amino acids (amino acid polymerization) will continue until a STOP codon is reached (UAA, UAG, and UGA).
Question: How much ATP will you need to expend to make a protein with 100 amino acids? How about a 150 amino acid protein? GOAL: Recognize and be able to articulate why protein synthesis is an energy consumptive process, and be able to discuss why it is critical for cells to regulate energy consumptive processes.
Termination
To create a functional protein, translation must end with the appropriate amino acid. If translation stops to soon, the protein will be too short and may not bend (configure) correctly. If it is too long, then it may not bend (configure) correctly. Termination is a critical process. Termination begins when a STOP CODON (UAA, UAG, and UGA) is reached. In eukaryotes, a releasing factor is used to separate the ribosomal subunits. KEY CONCEPT: The stop codon signals the end of the coded message.
Once completed, proteins can be further modified as fits their function (such as adding sugars). This is known as post-translational modification. The image below shows the posttranslational modifications needed in the production of insulin. Production starts with a ribosome-bound on the Rough Endoplasmic Reticulum (RER). Processing will occur in the RER and in the Golgi body. This is only one example of posttranscriptional modification, and a majority of proteins require such modifications before they are functional. [NOTE: as a general rule, there is a less extensive posttranscriptional modification in prokaryotes, but they have numerous proteins that do require modification].
Daily Challenge
In your own words, describe the process of translation. Discuss initiation, elongation, and termination. Make sure that you discuss the P and A site, as well as the importance of the start and stop codon. Afterwards, give a BRIEF discussion on how this is an energy consumptive process that needs to be regulated.
Optional Challenge: Genomics and Proteomics
Read the following articles: A brief guide to genomics - NIH fact sheet Transcriptome - NIH fact sheet Proteomics
The genome can be seen as the genetic potential of an individual (think Genotype), while the proteome shows what is actually produced at a given time, under a given condition (consider this the phenotype). Provide a discussion of the importance of genomic and proteomic studies in modern biological research, and make sure that you provide a description of both the genome and the proteome of an organism.
Optional Video
This video deals with advanced topics, so I give it to you in case you are curious.
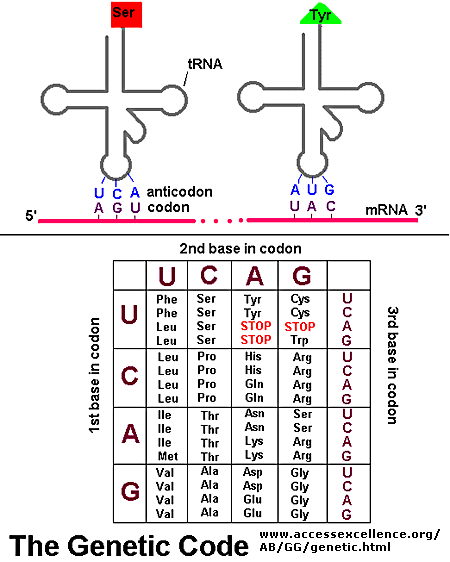
Translation is the process of "reading" mRNA and using the code to construct a protein. But what is the code? The nucleotide language of mRNA can be divided into codons. Three sequential nucleotides that represent a genetic (nucleotide) word. So, how do you read this code or nucleotide language?
In the image to the right, you have sequential nucleotides divided up into codons. Notice that AUG is listed as Codon 1. This is important!AUG is the Universal Start Codon. Nearly every organism (and every gene) that has been studied uses the three ribonucleotide sequence AUG to indicate the "START" of protein synthesis (Start Point of Translation).
As we will see tomorrow, it takes more than a start codon to initiate transcription, but for now, just remember that this is the codon that indicates the START point of the instructions on how to make a protein.
The start codon established the Reading Framefor translation. From the start codon, every three sequential nucleotides will be viewed as a codon. This is critical! Mutations can affect reading frames. For example, if a nucleotide is inserted between codon 2 and 3 (G G), would you have the same reading frame down stream? What if you deleted the first nucleotide of codon 4? What is the effect of changing the reading frame? What would happen to the resulting protein?
Insertions and deletions can change reading frames, but point mutations can also occur. In this case, one nucleotide is change to a different nucleotide. What would happen if the final nucleotide of condon 3 were changed to a C? To an A? How about the second nucleotide in codon 4? Change the U to an A, what happens?
Each codon is a "genetic word," and refers to a specific amino acid (thus changes to these words can result in changes to final proteins). The tRNA is the agent of translation. On one end of the tRNA, you will find an anti-codon. Anti-codons are complimentary to codons. Example: Codon 1 reads AUG. The corresponding tRNA would have an anticodon reading UAC. (Question: Would these be antiparallel?). Codon 2 reads ACG, so the anticodon would read UGC. Oppisite the anticodon, you will find a binding site for a specific amino acid.
An amino acid can be attached to the free 3' end of the tRNA. There is a class of enzymes capable of attaching an amino acid to a tRNA: Aminoacyl tRNA Synthetase. Below is a very basic cartoon of how an amino acid is added to a tRNA.
Note that an ATP is needed to complete the binding. There is an Aminoacyl tRNA Synthetase for each tRNA-Amino Acid combination.
Below is a diagram showing the pairing of codon to anticodon. The diagram also contains a version of the Genetic Code table, showing the relationship between codon and amino acid.
Note that three codons are referred to as STOP codons: UAA, UAG, and UGA. These are used to terminate translation; they indicate the end of the gene's coding region. What would happen if you lost a Stop codon?
Challenge
How the change of one amino acid caused the configuration change in the protein. Amino Acids are coded due to a codon. In Sickle Cell Anemia, there is a mutation that changes one amino acid: Valine (Val) is found in place of Glutamic Acid (Glu). If we look at the sequences, we find that at the sixth codon, the wild type reads GAG, but the sickle type reads GUG. This is a single nucleotide polymorphism. At the end is a video to explain SNPs (pronunciation: Snips)
Here is the mRNA code for the wild type (non-mutant) and mutant β-hemoglobin molecule.
Today, consider the consequence of a SNP. What would happen if it occurred in a Start or Stop codon. What would happen if an AAG upstream (before) the start codon had a SNP that changed the second nucleotide from an A to a U? What would happen if CGC changed to CGG? How about CAU to GAU?
After considering these, and looking at the video, what are some of the consequences of a SNP? How could a SNP either stop translation or prolong it? Are all of the results harmful, or can they be neutral?

. Available at: http://upload.wikimedia.org/wikipedia/commons/4/48/Lac_operon1.png. Accessed November 6, 2012.")











, two cysteines bound together by a disulfide bond.")






. Available at: http://upload.wikimedia.org/wikipedia/commons/thumb/2/25/Insulinpath.png/339px-Insulinpath.png. Accessed November 1, 2012.")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}